Database and API Design¶
Overview¶
The entire database ER diagram is as shown below. The space is divided logically into “Corpus”, “Trees”, “Propositions”, “Senses”, “Names”, “Coreference” and “Ontology.”
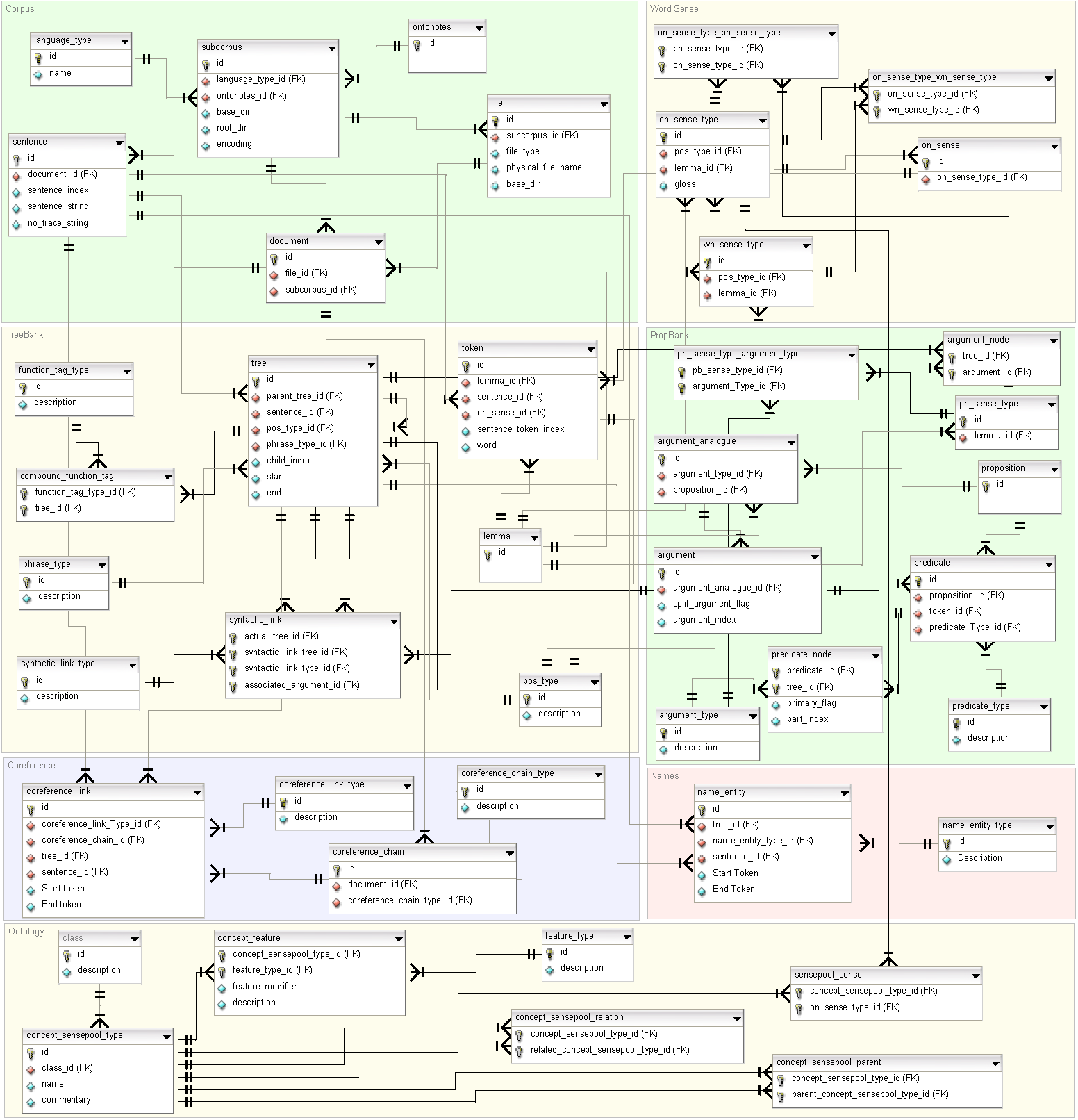
The OntoNotes database ER diagram
We will look at the individual group of tables in the following subsections. The design of the database was chosen to be close as possible to the object-oriented structure of the overall OntoNotes design. It should also be noted that we have traded-off database design principles for ease of querying in the computational semantics space. That is, we have not tried to reach the third or higher database normal form. The advantage of this is that there is a seamless connection between the database world and the object-oriented world, and therefore complex queries can be answered either using SQL or using the methods of the objects themselves. It should also be noted that the primary keys of almost all the tables are composite formed using the concatenation of individual foreign keys separated by the “@” symbol. This facilitates understanding the object in most cases by just looking at its primary key. The seamlessness is further enhanced by the use of the same primary keys for object ids. We decided to use the MyISAM database engine, and enforce only the primary key constraints, as adding foreign key constraints add a significant overhead on the queries, and since the data are not likely to be updated, it is only at load time that the constraint checking is important. Constraint checking is hence done in the DB Tool logic. Even though MyISAM ignores foreign key constraints, we do include them in table create statements to document them.
Corpus¶
The collection of tables that manage the corpora are shown in Figure 1.1 The “ontonotes” table stores the main ontonotes id. There can be more than one “subcorpus”’ (subcorpora) associated with the OntoNotes table. Each subcorpus represents an arbitrary set of documents, by default all the documents for a given source. The “subcorpus” table has associated with it a “language_id” and can contain many “file”s. Each file can contain one or more “documents”. In the current situation, there is only one document per file in all subcorpora, but this might change in the future. Then, each document has associated with it a list of “sentences”
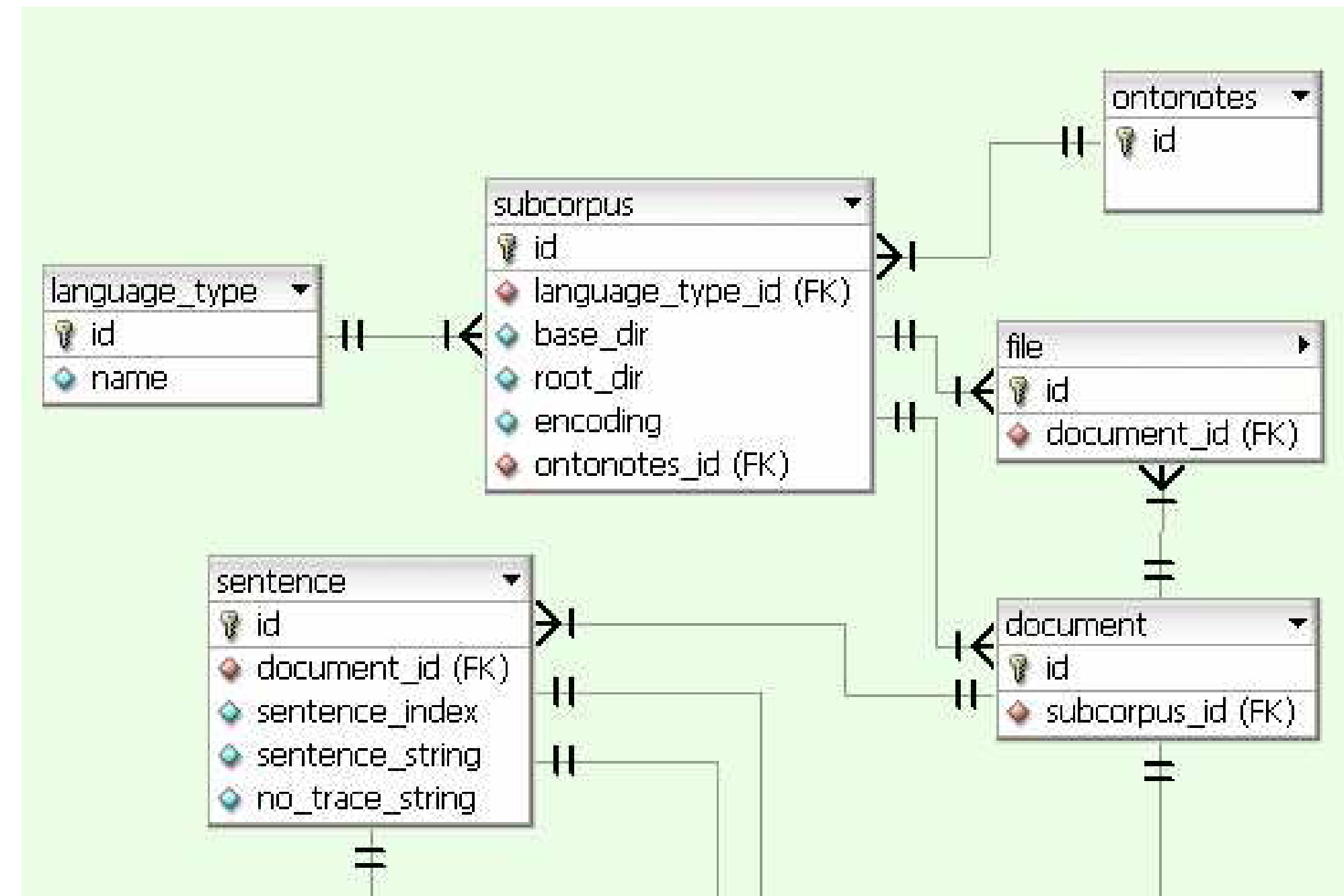
Corpus Tables
Trees¶
The tables that are used to represent the Treebank are shown in Figure 1.2. The central table in this region is the “tree” table which contains all the nodes in all the trees in the corpora. Since we use the Treebank tokenization as the lowest granularity for identifying elements in the corpus, we show the “token” table in this region. It contains back-pointer to the sentence and the tree that it belongs to. Associated with the tree nodes are various meta tags such as the part-of-speech tag, stored in the “pos_type” table, the phrase types, stored in the “phrase_type” table, the function tags stored in the “function tag” table, and the syntactic links stored in the “syntactic_link” table.
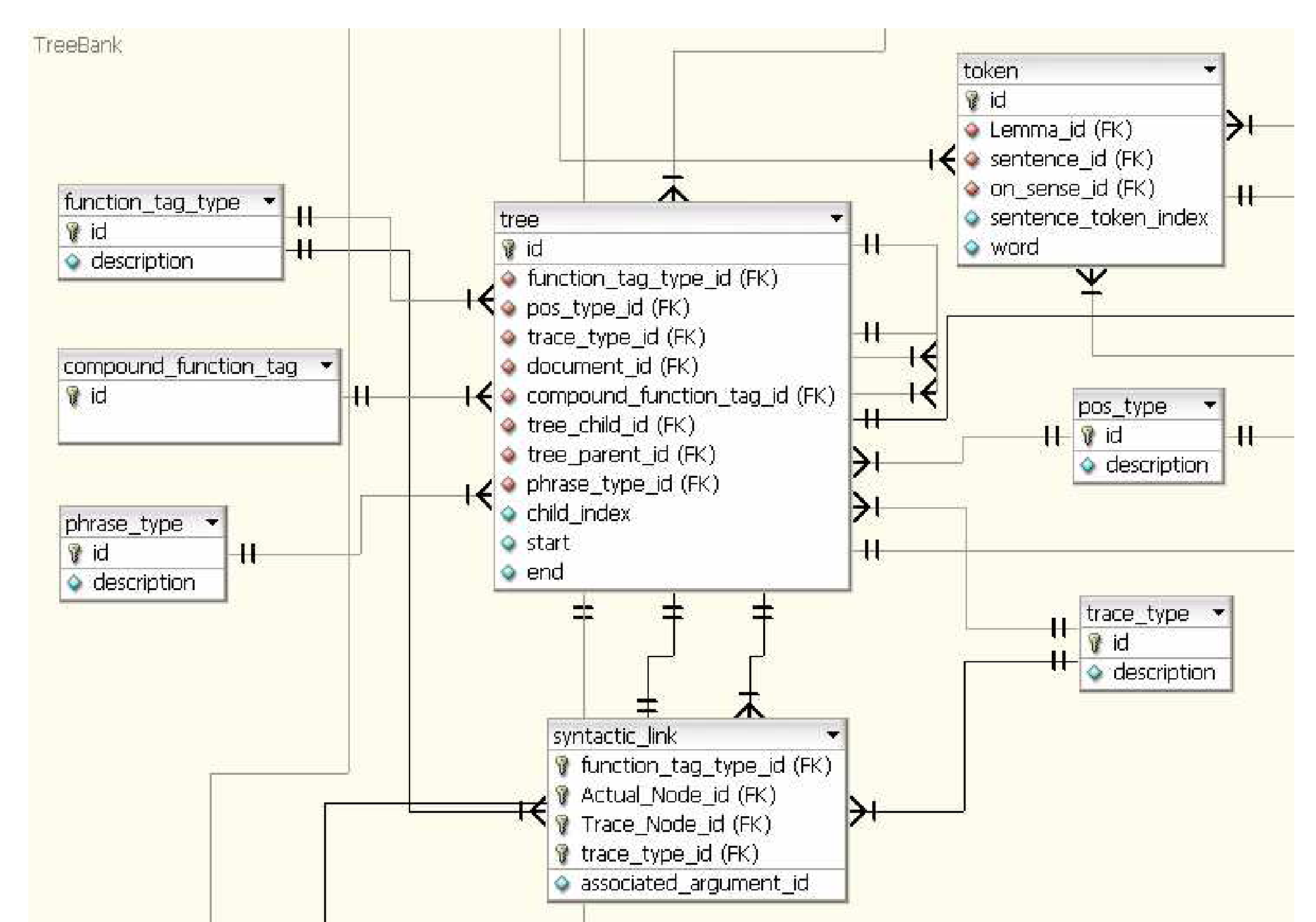
Treebank Tables
Propositions¶
The tables that depict the PropBank information are shown in Figure 1.3. At the core is the “proposition” table which stores all the propositions in the corpora. The “predicate” and the “predicate_node” tables store the many-to-many relationship that can be associated with the predicates and the nodes in the tree. The same is the case with the “argument” and the “argument_node” table. The “argument_type” and the “predicate_type” tables store the predicate and argument types as defined in PropBank.
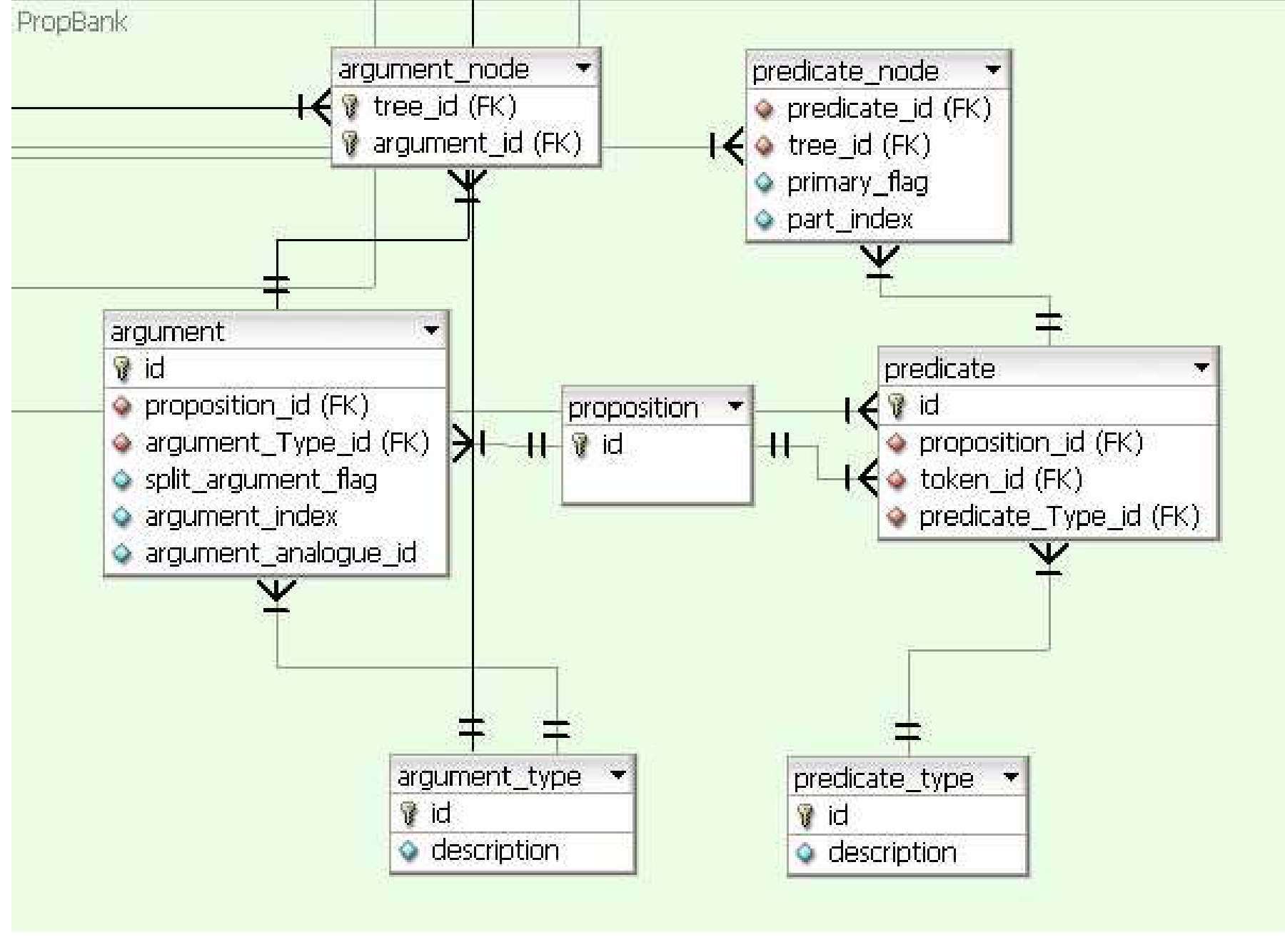
Proposition Tables
Word Senses¶
The OntoNotes word sense is stored in the “on_sense” table shown in Figure 1.4 There are connections between the OntoNotes sense and the Proposition Bank’s frames which are captured in the “on_sense_type_pb_sense_type” table. The WordNet senses which are grouped to form the OntoNotes sense and occasionally vice-versa are captured by the “on_sense_type_wn_sense_type” table. The frames files in PropBank restrict the types of core arguments that a predicate can take, and this information is stored in the “pb_sense_type_argument_type_table” which then has connections to the “argument_type” table in the PropBank table space. It should be noted that the WordNet mapping are only available for the English part of the corpus. There is no equivalent in the Chinese part.
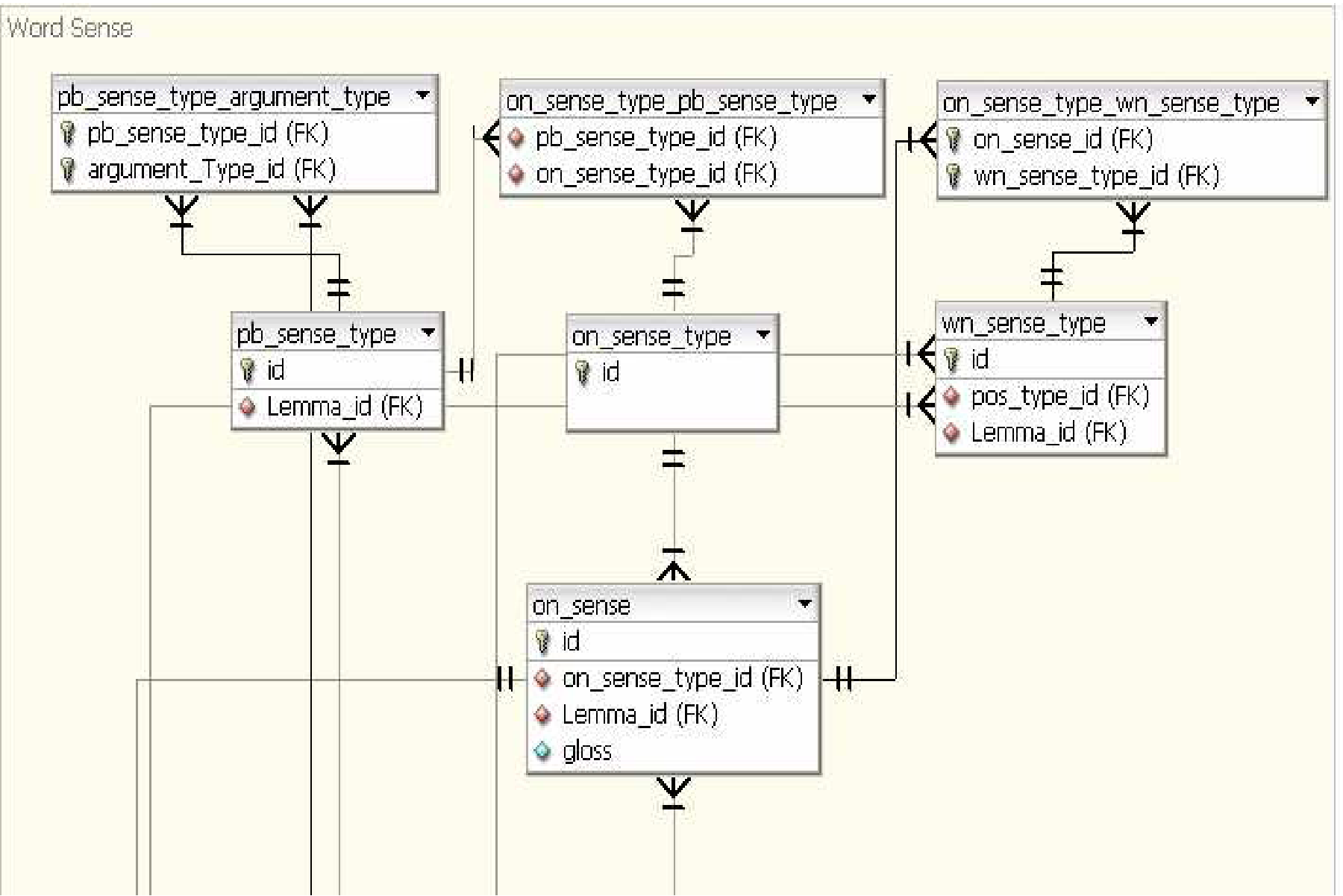
Word Sense Tables
Name¶
The Name Entity relations are stored in the “name_entity” and “name_entity_type” tables shown in Figure 1.5 These are then connected to the respective tokens in the sentence, and are also connected to the appropriated nodes in the tree whenever there is a possible alignment.
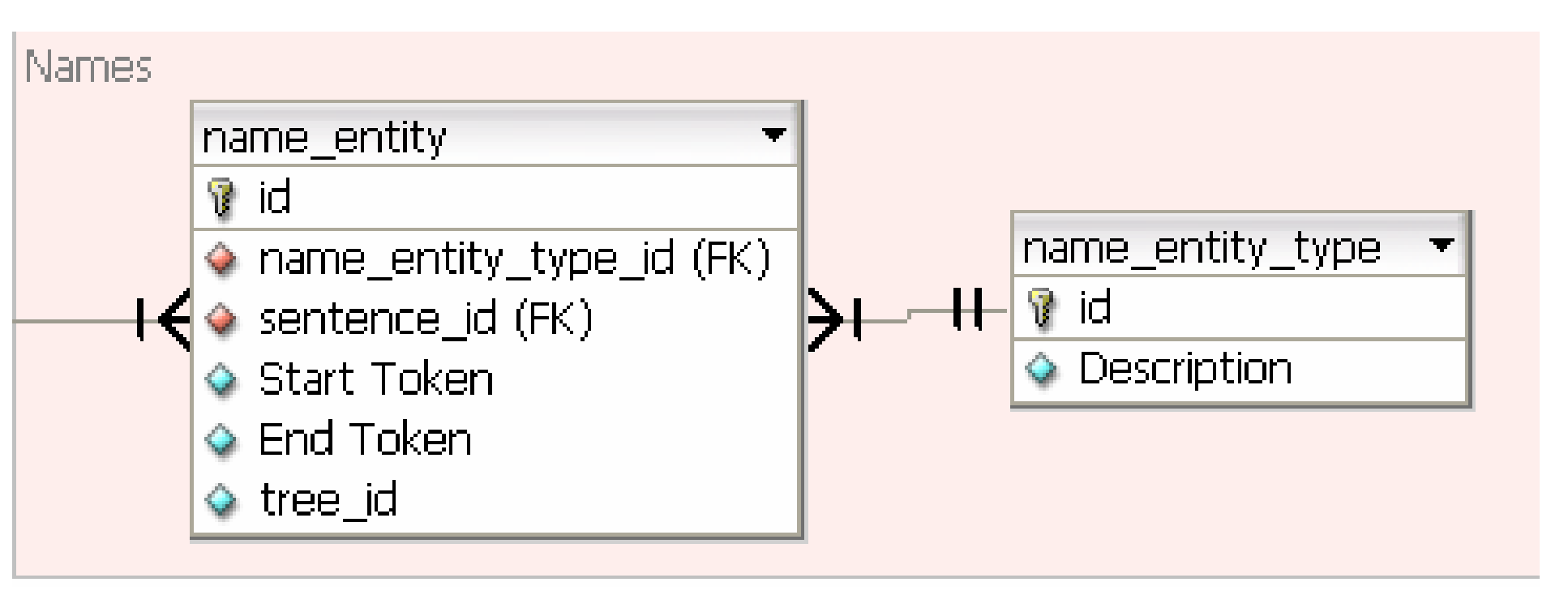
Name Tables
Coreference¶
The “coreference_link” and “coreference_chain” tables, shown in Figure 1.6, in the Coreference table space store the information required to capture equivalent entities in the corpus. They also have information on the string span in the corpus that they are associated with, and in case of alignments (which in most cases is true since the coreference annotation was done on top of the treebank, withholding some exceptional entities) the node information is stored in the “coreference_link” table.
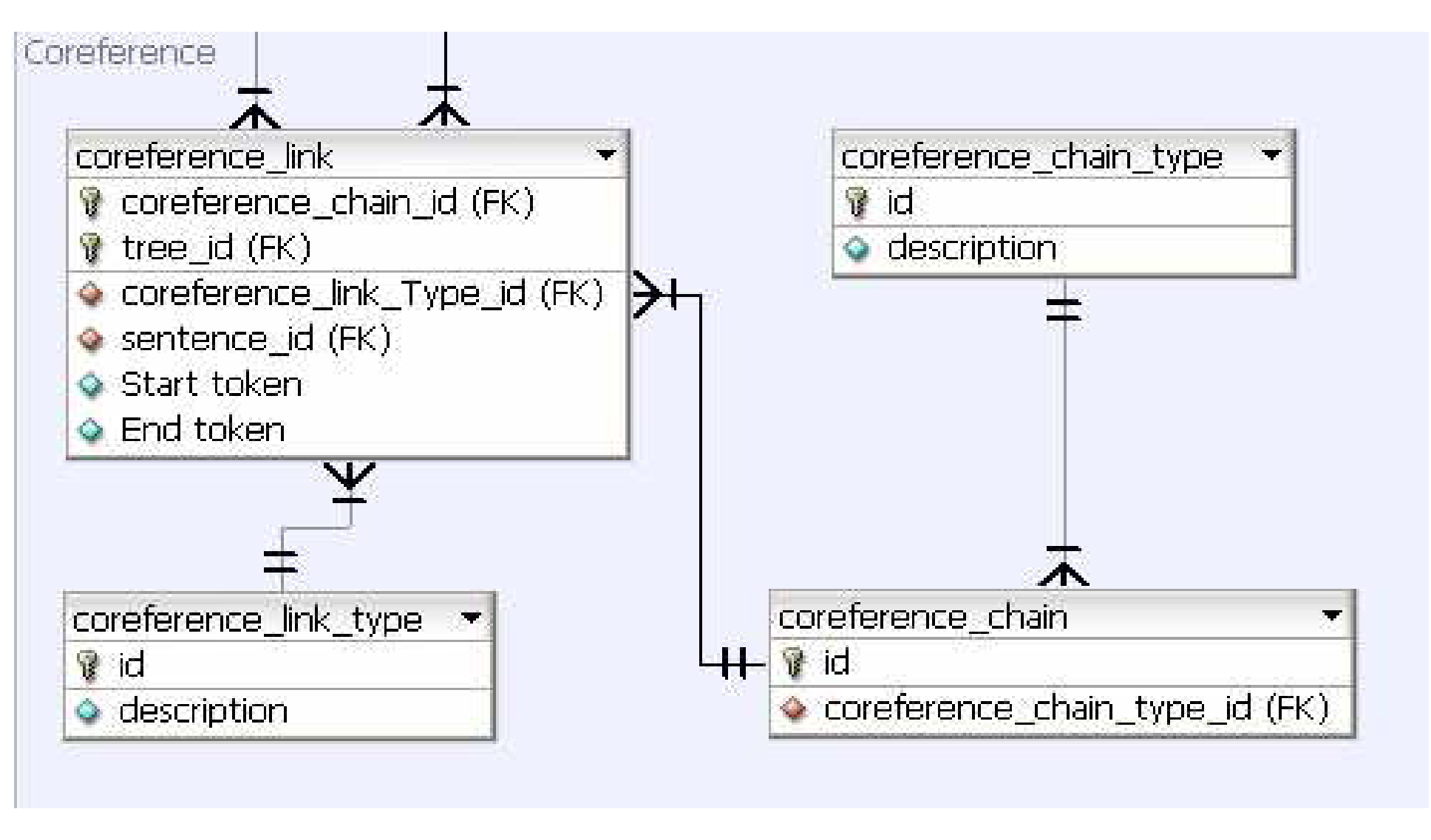
Coreference Tables
Banks¶
Each annotation project created a set of related data which is called a “bank” of that annotation – in accordance with Treebank, PropBank, etc. Each bank has three representations: as a table in the database, as as a python object, and as a file. The correspondences are:
Bank Name Database Table Python Module Extension tree tree on.corpora.tree .parse sense on_sense on.corpora.sense .sense proposition argument, predicate on.corpora.proposition .prop coreference coreference_link on.corpora.coreference .coref name name_entity on.corpora.name .name speaker speaker_sentence on.corpora.speaker .speaker parallel parallel_sentence, parallel_document on.corpora.parallel .parallel
This elucidates the connection between the three levels of representation – text files, python objects and database tables. There are actually multiple database tables used to represent the data. In the correspondence table above, we’ve listed the database table which contains the actual annotation alongside the python module which contains that bank. For example, for word sense annotation, we list the on_sense table along side the on.corpora.sense module. The on_sense table has the actual annotation, including fields for the lemma, sense, and a pointer to the annotated word in the tree. The on.corpora.sense module describes a on.corpora.sense.sense_bank containing on.corpora.sense.sense_tagged_document instances which contain on.corpora.sense.on_sense instances. This also elides the supporting annotation, such as the sense inventories needed to interpret and ground the sense annotations. For the details on each bank, look up the documentation for the referenced python module.